June 10, 2026
Seven AI models translated the same Hebrew idiom. None of them got it right.
We've been running translation tests on MachineTranslation.com for a while. Most of them confirm what you'd expect: newer models outperform older ones, more capable architectures handle nuance better, and running comparisons across multiple models surfaces disagreements that a single-model workflow would miss entirely.
This test did something different.
We ran a two-word Hebrew idiom through seven AI models simultaneously. The phrase is common in everyday Israeli Hebrew, the kind of colloquial expression a native speaker uses without thinking about it. When we looked at the results, we found something the previous Spanish idiom test hadn't produced: not a single model returned the correct meaning. Not one.
That earlier test (which we documented here) showed that models can reach the right answer while still disagreeing with each other. Three models produced correct but non-identical translations of a Spanish idiom, each defensible, none equivalent. The lesson there was about disagreement within correctness.
The lesson here is different. Seven models failed, but they failed in three categorically distinct ways. And the pattern of those failures tells us something about what idiomatic competence in AI actually looks like, at what point in a model's development it starts to appear, and where it still falls short in the most capable models we tested.
Table of contents
- The idiom and what it actually means
- The test
- Three failure modes in one test
- The capability gradient inside the GPT family
- The output nobody will look at twice
- What the Cohere models reveal about training data
- The SMART consensus problem
- What I don't know yet
The idiom and what it actually means
לאכול סרטים (le'echol sratim) translates literally as "to eat movies." It means nothing of the sort.
In Israeli Hebrew, the phrase describes someone who is being paranoid — specifically, someone who is constructing a fictional version of events in their head and treating it as real. "You're eating movies" is roughly equivalent to "you're making things up" or "you're being paranoid," but neither of those captures the precise nuance. The idiom implies an active, almost creative process. The person isn't just anxious. They're authoring a scenario.
The distinction matters for translation. "To be paranoid" is the closest single English equivalent. But paranoia can be reactive — a response to real signals, however misread. לאכול סרטים is more specific: it names the act of fabricating a narrative that has no basis in what's happening. You might tell someone "אתה אוכל סרטים" ("you're eating movies") when they accuse you of something you didn't do, or when they've built up an entire story in their head about a situation that doesn't exist. It's the translation of a mental movie, not a reaction to reality.
This specificity makes it a useful stress test for AI translation. The correct rendering requires not just recognising that the phrase is idiomatic rather than compositional, it requires knowing the precise emotional and cognitive territory the idiom occupies. Models that have encountered the phrase in training data with sufficient contextual variety might find it. Models that haven't will have to guess, and the nature of their guess will reveal where their understanding breaks down.
The test
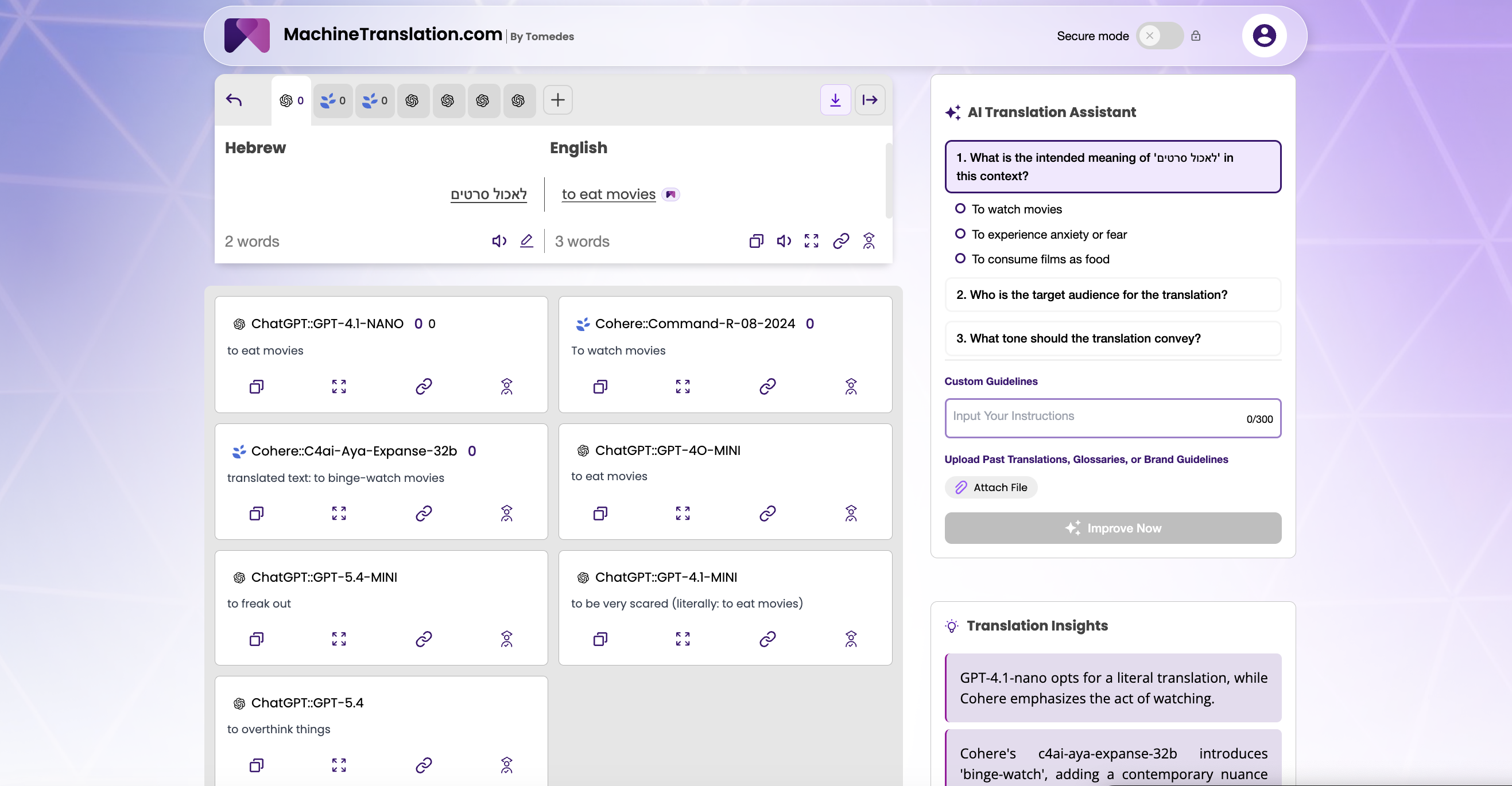
We entered לאכול סרטים into MachineTranslation.com's internal testing environment and ran the full model comparison. The platform queried seven AI models simultaneously and returned outputs alongside a Translation Insights analysis and contextual questions from the AI Translation Agent.
The AI Translation Agent's first question was: "What is the intended meaning of 'לאכול סרטים' in this context?" — with three options: "To watch movies," "To experience anxiety or fear," or "To consume films as food." Option 2 is the closest of the three to the correct meaning, though it still undersells the fabrication aspect. Even the platform's own disambiguation didn't fully capture the idiom. That detail will matter later.
Here are all seven model outputs:
| Model | Output | Failure type |
|---|---|---|
| ChatGPT::GPT-4.1-NANO | "to eat movies" | Literal |
| ChatGPT::GPT-4O-MINI | "to eat movies" | Literal |
| Cohere::Command-R-08-2024 | "To watch movies" | Wrong-direction confident |
| Cohere::C4ai-Aya-Expanse-32b | "to binge-watch movies" | Wrong-direction confident |
| ChatGPT::GPT-5.4-MINI | "to freak out" | Partial, emotional register only |
| ChatGPT::GPT-4.1-MINI | "to be very scared (literally: to eat movies)" | Partial, with transparency |
| ChatGPT::GPT-5.4 | "to overthink things" | Partial, cognitive register only |
Three failure modes in one test
The seven outputs don't represent seven random misses. They fall into three recognisably different patterns of failure, and understanding those patterns is more instructive than the zero-correct headline.
The literal group (GPT-4.1-NANO and GPT-4O-MINI) returned "to eat movies." A faithful reproduction of the component words with no inference about idiomaticity. MachineTranslation.com's Translation Insights panel noted: "GPT-4.1-nano opts for a literal translation, while Cohere emphasises the act of watching." These models processed the phrase as two vocabulary items and translated accordingly. There is no evidence they considered whether the combination of those items might carry a different meaning.
The wrong-direction confident group (both Cohere models) recognised the word סרטים (movies/films) and built outward from it. Command-R returned "To watch movies." C4ai-Aya-Expanse went further: "to binge-watch movies," with the Translation Insights panel noting it was "introducing 'binge-watch', adding a contemporary nuance." These outputs are not literal failures. They are inference failures — confident, fluent, and pointed squarely in the wrong direction.
The partial group (GPT-5.4-MINI, GPT-4.1-MINI, GPT-5.4) approached the emotional or cognitive territory of the idiom without landing on the correct meaning. "To freak out" has the right emotional pitch but the wrong action. "To overthink things" has the right cognitive frame but the wrong specific activity. "To be very scared" reaches for the emotional register. All three are meaningfully closer to correct than either group above, and categorically different in kind from what the first four models produced.
The capability gradient inside the GPT family
Looked at in order, the GPT outputs tell a sequential story.
GPT-4.1-NANO and GPT-4O-MINI returned identical literal translations. Neither showed any signal of idiomatic recognition — the phrase was processed as transparent language, and the components were translated individually.
GPT-5.4-MINI moved to an emotional register: "to freak out." This is the first output that suggests the model recognised the phrase as something other than a literal instruction about eating cinema. It reached for an emotional equivalent. The reach was imprecise, but it was a reach.
GPT-4.1-MINI did something more unusual, which gets its own section below.
GPT-5.4 arrived at "to overthink things" — the closest output in the set and, as far as capability generation goes, the ceiling of what was tested. "Overthinking" implies a mental process that spirals beyond what's warranted. לאכול סרטים implies a similar spiral, but the specific content of that spiral is fabricated rather than exaggerated. You overthink when you ruminate on what's real. You eat movies when you invent what isn't.
GPT-5.4 got the genre right. It didn't get the story right.
What this progression suggests is that idiomatic recognition scales with model capability, but in stages. There appears to be a threshold at which a model begins to recognise that a phrase is idiomatic at all, and a second, higher threshold at which it can reproduce the correct idiomatic meaning from training data. GPT-5.4 appears to be past the first threshold and short of the second. The smaller GPT models appear not to have crossed the first.
The output nobody will look at twice
GPT-4.1-MINI returned: "to be very scared (literally: to eat movies)"
Every other output in this test gave a single translation and moved on. This one gave a translation and then, in parentheses, disclosed the literal reading it had decided not to use.
Whether "to be very scared" is the right idiomatic rendering is a separate question — it's imprecise in the same ways the other partial outputs are imprecise, landing on emotion rather than on the act of fabricating scenarios. But the structural choice to include the parenthetical is worth examining on its own terms.
A model that tells you "here is what I think this means, and here is the literal reading I chose not to use" is providing something the other models aren't: a traceable reasoning path. You can evaluate whether the idiomatic choice makes sense against the literal. You can catch the error if the model is wrong. With the other six outputs (including the more accurate "to overthink things" from GPT-5.4), there is no such trail. The model delivers a translation and offers no indication of the choices made to produce it.
In high-stakes translation contexts, that transparency has practical value independent of accuracy. A wrong answer that shows its reasoning is more recoverable than a confident wrong answer that shows nothing. If a reviewer sees "to be very scared (literally: to eat movies)," they have a signal that the translation is uncertain and the literal is unusual — an invitation to investigate. If they see "to overthink things," they see a fluent English phrase with no flag attached, and may accept it without review.
Whether the parenthetical was consistent model behaviour or specific to this phrase, I don't know. It stood out from six outputs that showed no internal uncertainty at all.
What the Cohere models reveal about training data
The Cohere failures require a different explanation from the GPT literal group, and the difference is instructive.
GPT-4.1-NANO and GPT-4O-MINI produced "to eat movies" because they translated word by word without inference about idiomaticity. The result is obviously wrong to any English reader. Nobody eats movies.
The Cohere models did something more sophisticated and more dangerous. They recognised the word סרטים, inferred that the phrase was about cinema or film, and returned fluent English translations that reflect that inference. "To watch movies" is natural English. "To binge-watch movies" is current, contemporary English. Neither is correct, but neither flags itself as wrong.
This matters in practice. A literal translation error announces itself. "To eat movies" would immediately prompt a human reviewer to check the source. "To binge-watch movies," embedded in a translated document or communication, would likely pass an initial review. The error travels.
What this suggests about training data is speculative but worth naming: the Cohere models appear to have stronger associations between סרטים and its literal meaning (movies, cinema) than between the full phrase לאכול סרטים and its idiomatic use. This is a plausible consequence of training data distribution — Hebrew colloquial speech is likely underrepresented in large text corpora relative to formal written Hebrew and non-Hebrew text, and the idiomatic use of the phrase may appear less frequently than the word סרטים in non-idiomatic contexts. A model that has seen the word many times in movie-related contexts and the idiom rarely or never will default toward what it knows.
The result is a model that is confident in its error, which is the worst kind.
The SMART consensus problem
The value of consensus (which is real, and demonstrable in higher-quality test cases) depends on a baseline where most models are attempting the correct meaning and disagreeing on phrasing. When the dominant cluster in the comparison set is wrong, consensus finds the centre of the dominant cluster. In this test, the centre was a literal translation that had nothing to do with the idiom.
For Hebrew to English translation workflows that include idiomatic or colloquial content, this has a direct implication. The divergence between outputs is itself the signal: when models cluster into the failure patterns visible in this test, that clustering indicates content that needs human review rather than automated synthesis. The SMART output tells you where the consensus landed. The individual outputs tell you what the consensus was built from.
What I don't know yet
Several questions from this test don't have answers I can give with confidence.
1. Would context change the results?
The phrase was entered as a standalone two-word input. In natural Hebrew, לאכול סרטים appears in sentences — "אתה אוכל סרטים" (you're eating movies, i.e., you're being paranoid) usually follows a specific accusation or claim. Whether surrounding a sentence improves idiomatic recognition in any of these models is a test that hasn't been run.
2. Is the GPT-4.1-MINI parenthetical consistent?
The transparency of "to be very scared (literally: to eat movies)" suggests a model that has some mechanism for flagging its own uncertainty on idiomatic phrases. Whether this behaviour appears on other idioms (whether it's a pattern or a coincidence) would require testing across a broader sample.
3. How does this compare to other Hebrew idioms?
לאכול סרטים is common but not unusual. Hebrew has a dense stock of non-compositional idioms: "לשבור את הראש" (to break the head - meaning to rack one's brains), "לאכול את הראש" (to eat the head - meaning to nag relentlessly), "לשים את האצבע על הדופק" (to put one's finger on the pulse - meaning to stay current). Whether the same three failure clusters appear on different idioms, or whether this test reflects something specific to לאכול סרטים, is an open question.
4. Does GPT-5.4's output represent a ceiling?
"To overthink things" is the closest result in the set. It's wrong in a specific, nameable way — overthinking involves ruminating on what's real; לאכול סרטים involves fabricating what isn't. Whether a different prompt framing, or more contextual input, would push GPT-5.4 past that distinction is not something this test resolves.
What the test does confirm is consistent with the Spanish idiom comparison: idiomatic translation is a distinct capability from general translation quality, it scales with model generation in a visible gradient, and it fails differently depending on the model architecture and the training data distribution. The outputs in this test aren't noise. They're a readable record of where seven different AI systems break down on two words of colloquial Hebrew.
This post is based on internal testing on MachineTranslation.com's development platform. The multi-model version testing shown here is not yet publicly available. I'm sharing the finding because I think the observation is useful regardless of where you run your translations.
Try MachineTranslation.com — Pro Plan from $19/month · 24-Hour Unlimited Translations from $6
Pricing current as of June 2026 and subject to change.
About the author
Ofer Tirosh
Chief Executive Officer, Tomedes
Connect on LinkedIn →